零基础人工智能-第三篇 TensorFlow2.0 巧用 IMDB数据集影评好坏分类
2020-04-21
IMDB数据集介绍
IMDB影评数据集使用
1. 使用tf.keras框架,和数学库numpy
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
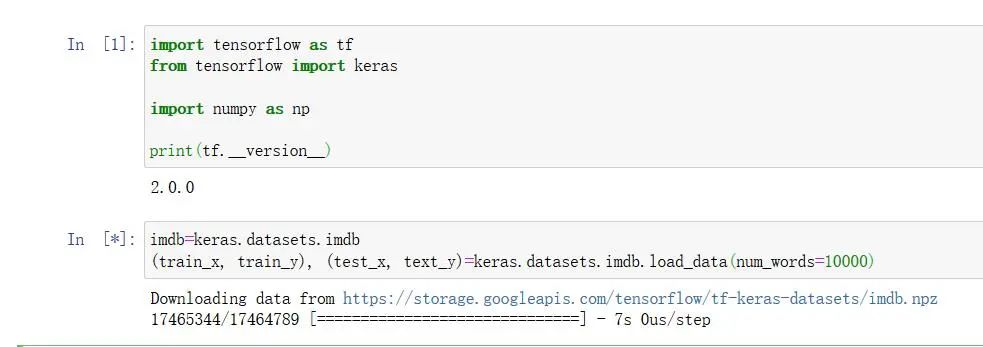
2. 下载imdb
imdb=keras.datasets.imdb(train_x, train_y), (test_x, text_y)=keras.datasets.imdb.load_data(num_words=10000)
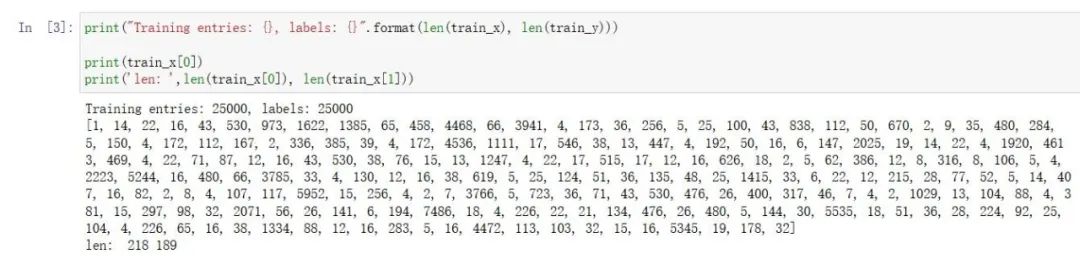
3. 查看数据
print("Training entries: {}, labels: {}".format(len(train_x), len(train_y)))
print(train_x[0])
print('len: ',len(train_x[0]), len(train_x[1]))
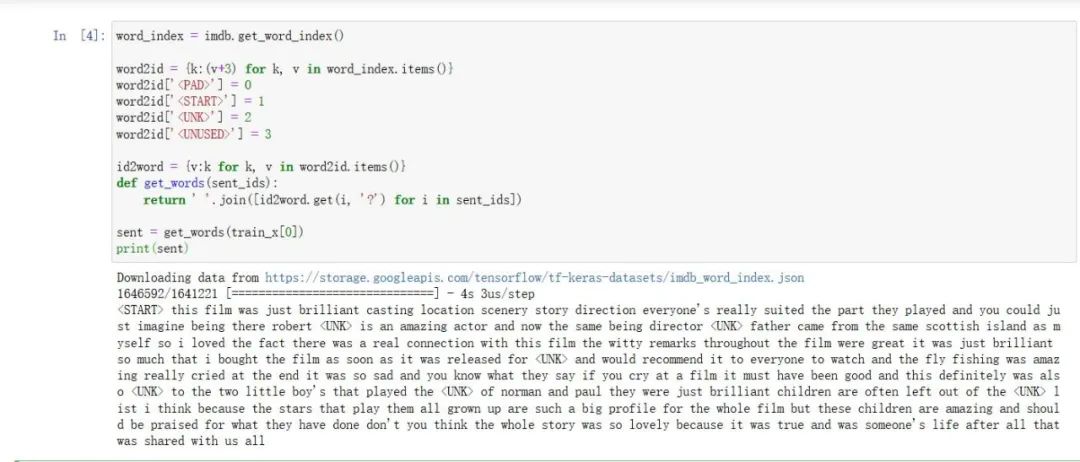
4.创建数字id和词的匹配字典
word_index = imdb.get_word_index()
word2id = {k:(v+3) for k, v in word_index.items()}
word2id['<PAD>'] = 0
word2id['<START>'] = 1
word2id['<UNK>'] = 2
word2id['<UNUSED>'] = 3
id2word = {v:k for k, v in word2id.items()}
def get_words(sent_ids):
return ' '.join([id2word.get(i, '?') for i in sent_ids])
sent = get_words(train_x[0])
print(sent)
5. 准备数据
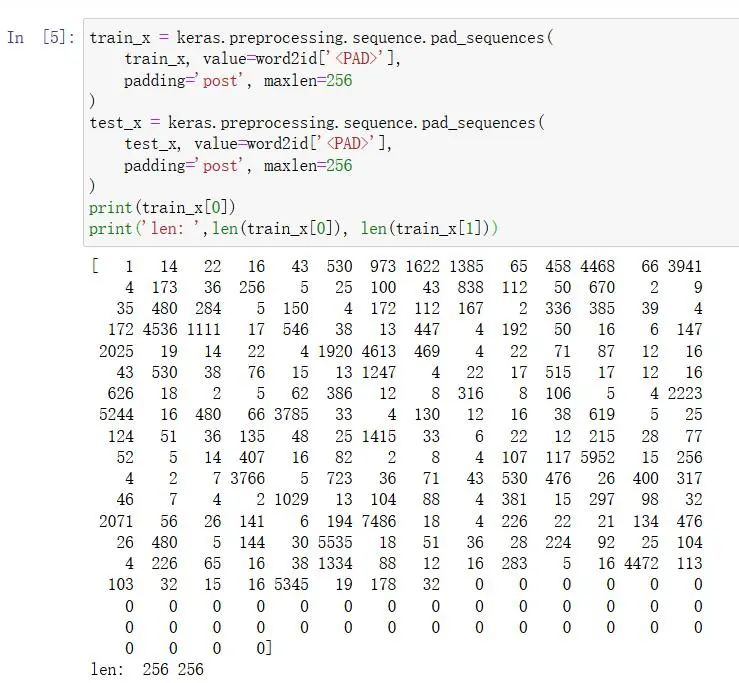
train_x = keras.preprocessing.sequence.pad_sequences(
train_x, value=word2id['<PAD>'],
padding='post', maxlen=256
)
test_x = keras.preprocessing.sequence.pad_sequences(
test_x, value=word2id['<PAD>'],
padding='post', maxlen=256
)
print(train_x[0])
print('len: ',len(train_x[0]), len(train_x[1]))
6. 建立模型
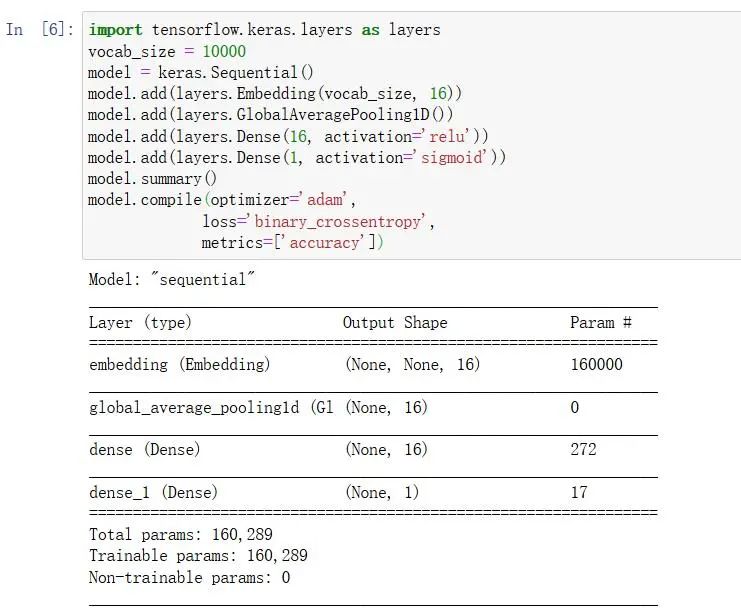
import tensorflow.keras.layers as layers
vocab_size = 10000
model = keras.Sequential()
model.add(layers.Embedding(vocab_size, 16))
model.add(layers.GlobalAveragePooling1D())
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
7. 模型验证与校准
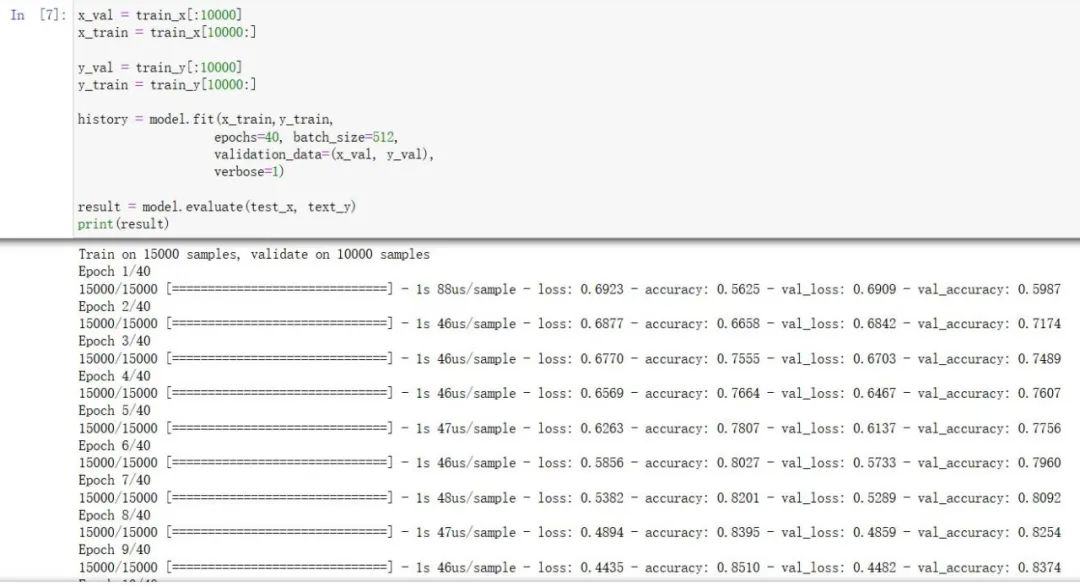
x_val = train_x[:10000]
x_train = train_x[10000:]
y_val = train_y[:10000]
y_train = train_y[10000:]
history = model.fit(x_train,y_train,
epochs=40, batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
result = model.evaluate(test_x, text_y)
print(result)

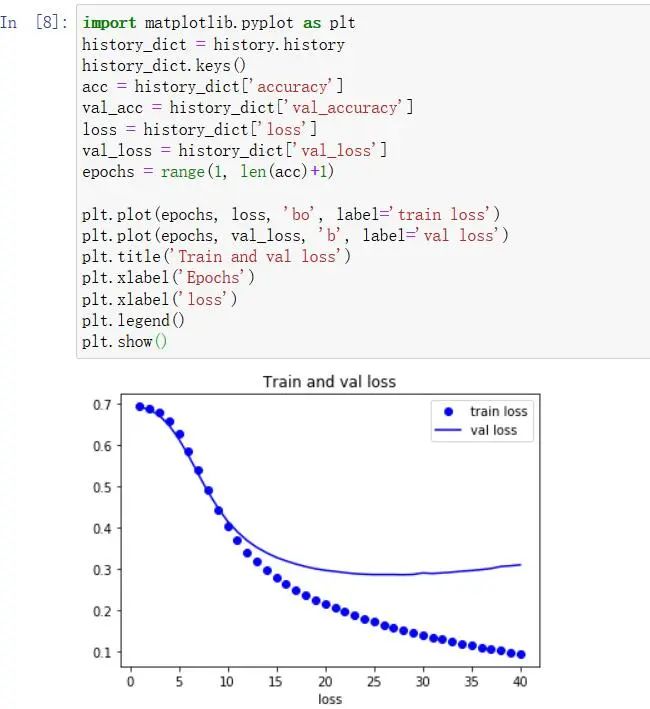
import matplotlib.pyplot as plt
history_dict = history.history
history_dict.keys()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, loss, 'bo', label='train loss')
plt.plot(epochs, val_loss, 'b', label='val loss')
plt.title('Train and val loss')
plt.xlabel('Epochs')
plt.xlabel('loss')
plt.legend()
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
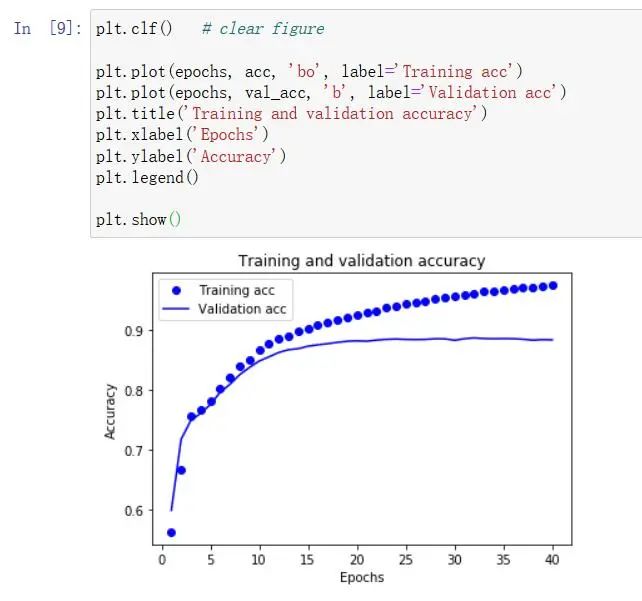
可以看出,训练损失值随着每个epoch而减少,并且训练精确度随epoch增加而增加。这在使用梯度下降优化时是符合预期的。

以后的教程中,我们将进一步学习如何使用回调自动执行此操作。

一起来期待一下吧~


最新动态
警告!你有一份OpenClaw(龙虾) “抓虾”指南待查收!
OpenClaw(龙虾)智能体工具在企业办公场景的快速普及,带来了新的安全治理挑战。文章分析了OpenClaw的风险特征:具备外部联网、本地资源调用、自动化任务执行等能力,可能绕过企业安全边界。提供了终端安装检查、网络访问监控、行为审计等四维排查方法,并介绍了"风铃"系统的Agent行为检测能力。建议企业建立面向Agent类应用的长期治理机制,而非仅针对单一产品的应急处理。
2026-03-16
漠坦尼十周年庆典圆满礼成 | 拾光筑梦 · 同心致远
杭州漠坦尼科技庆祝成立十周年,举办"拾光筑梦·同心致远"主题庆典。活动回顾十年奋斗历程,总经理钱轶锋发布聚焦AI的未来战略。庆典包含员工表彰、趣味互动和幸运抽奖等环节,感谢全体员工和合作伙伴的支持,展望下一个十年的发展蓝图。
2026-03-09
欢度新春,安全守护不打烊 | 2026马年春节值守进行时
2026马年春节假期,漠坦尼安全团队将提供7X24小时不间断服务,确保客户业务安全无忧。现场和远程均有专人值守,值班工程师名单及联系方式已公布。公司春节假期为2月14日至24日,共11天,25日正式上班。专业团队随时待命,守护您的春节安全。
2026-02-13
荣耀回响:时间轴上的奋进之迹
《荣耀回响:时间轴上的奋进之迹》回顾了漠坦尼2025年在网络安全领域的突破与成就。从2月发布卫鸢AI自动值守系统,到12月完成openGauss兼容性认证,公司全年在技术创新、行业认证和生态共建方面取得多项重要成果,包括获得多项安全检测证书、入选信通院典型案例集、亮相互联网大会等。这些成绩展现了漠坦尼在AI与网络安全融合应用领域的实力,为2026年的新征程奠定了坚实基础。
2026-02-11
权威认证 | 漠坦尼风铃横向威胁感知系统荣获《网络安全专用产品安全检测证书》
漠坦尼风铃横向威胁感知系统近日获得中国电子科技集团公司第十五研究所颁发的《网络安全专用产品安全检测证书》。该系统专注内网横向威胁感知,通过自主研发技术实现无侵入部署,精准捕获攻击者渗透行为。漠坦尼成立于2016年,为多行业提供一体化网络安全解决方案。此次认证彰显了产品的安全性与可靠性。
2026-01-16